Bilancování využití území¶
Jednou z typických GIS úloh je tvorba bilancí vybrané datové sady za území. V tomto případě jde o ukázku bilancování dat tzv. současného stavu využití území Prahy. Tato data jsou volně dostupná na rozhraní IPR Praha spolu s metadaty o tomto datasetu. Pro lepší přehled je možné si je prohlédnout v aplikaci Atlas 5000, kde jsou v sekci Využití území.
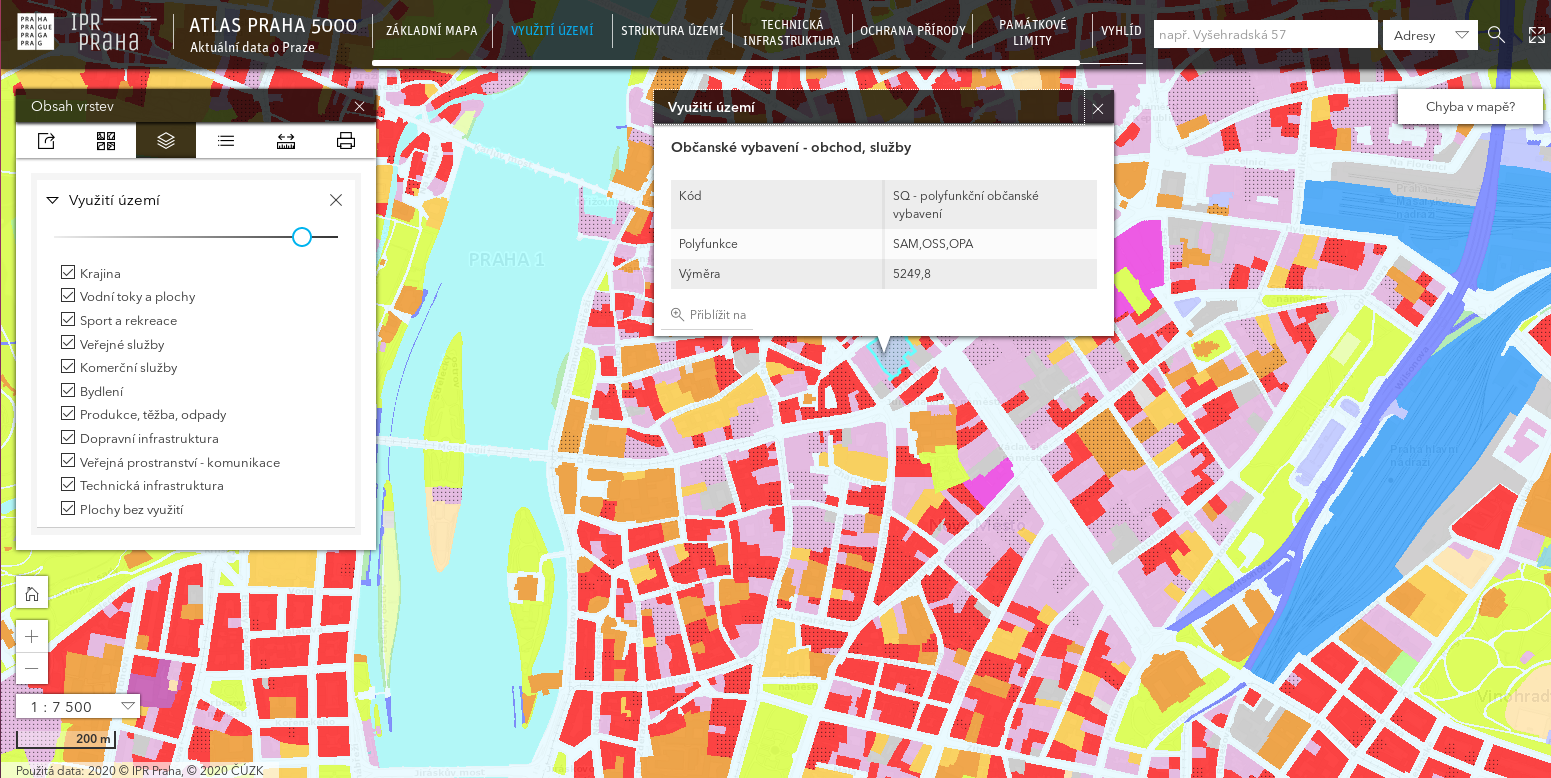
Obr. 199 Ukázka datové sady Současný stav v aplikaci Atlas 5000.¶
Tato datová sada souvisle pokrývá celé území Prahy pomocí malých, nepřekrývajících se plošek. Každá ploška má jednoznačně definované různé atributy, mezi nimi i atribut Kód. Vysvětlní každého kódu je možné najít v metadatech této sady.
V legendě je vidět, že se jednotlivé kódy shlukují do skupin.
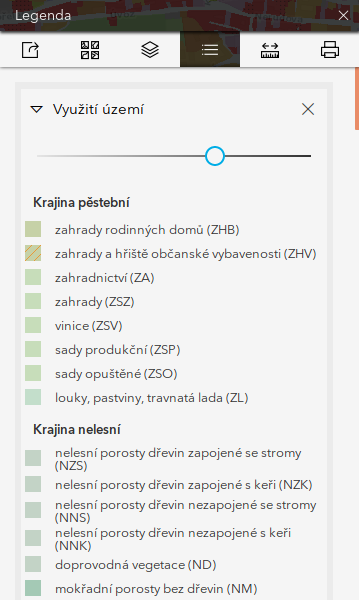
Obr. 200 Náhled do legendy s ukázkou seskupování kódů.¶
Zadání¶
Cílem je získat přehled za různé administrativní jednotky o tom jaké je procentuální zastoupení jenotlivých skupin dle kódů využití území. Takovýto výsledek lze zobrazovat pomocí kartodiagramu, nebo použít pro samostatnou tabulku a grafy.
Příprava dat¶
stáhnout data
vyuziti_uzemiz rozhraní IPR Praha (nebo jsou předpřipravena v balíku dat)územní členění Prahy (jsou součástí balíku dat, nebo stáhnout z RÚIAN)
tabulka kódů a jejich členění (převedeno do tabulky
kody, součást balíku dat)
Před samotným provedením analýzy je potřeba udělat kontrolu geometrie pomocí nástroje Zkontrolovat Platnost. Tento nástroj je v menu . Datová sada využití území je spravována a vydávána pomocí ESRI technologie, která má jiné nastavení pro validitu geometrie. Na obrázku je vidět geometrii, která je pro ESRI nástroje vpořádku, ale pro QGIS není validní. Jedná se o tzv. self-intersection nebo samoprotnutí prstence.

Obr. 201 Ukázka problémové geometrie na vstupních datech.¶
Tento typ chyb lze opravit automaticky pomocí nástroje Opravit geometrie. Předpřipravená data prošla kontrolou a opravou geometrie. Rovněž by měli být validní i členění území.
Bilance se přepočítávají na různé prostorové členění. K dispozici jsou různé administrativní jednotky - katastrální území (KU), základní sídelní jednotky (ZSJ), městské obvody (MO), městské části (MČ) a další. V tomto případě budeme používat ZSJ a to pouze pro území Prahy 7. Důvodem je rychlost výpočtu a přehlednost v malém zvoleném území. Vybrané ZSJ je možné si uložit do samostatné datové vrstvy. Prvky územního členění mají určenou výměru. Je vhodné přidat nový atribut, do kterého se přepočte výměra. Pokud bychom pracovali s přirpavenou výměrou, tak by se mohlo stát, že by součty jednolivých částí přesně neodpovídali.
1. propojení dat využití a skupin¶
Jednotlivý plochy využití mají vždy určen atribut Kód.
Rozdělení kódů do skupin obsahuje tabulka kody. Ta je součástí GPKG.
Po načtení se zobrazí jako tabulka
bez geometrie. Obsahuje čtyři sloupečky - fid, kód, textový popis kódu a skupinu, do
které je kód zařazen.
Tyto hodnoty musí být přiřazeny ke geometrické vrstvě využití území.
Ve vlastnostech vrstvy vyuziti_uzemi v sekci Připojení se vytvoří nové
připojení.
Musí se připojit tabulková data kody na základě atributů s kódy u zdrojové
i cílové datové sady.
Ukázka připojení je na obrázku.
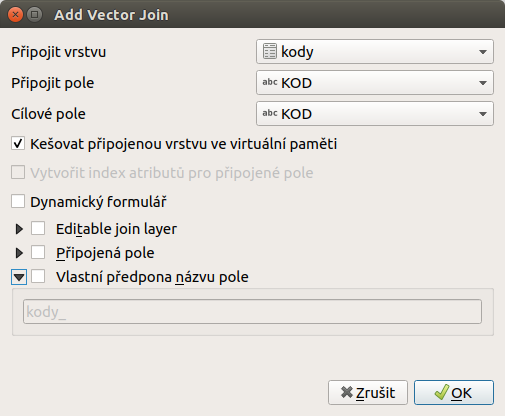
Obr. 202 Připojení tabulky kódů na vrstvu využití území.¶
Po připojení jsou nové atributy zařazeny nan konec atributové tabulky.
Varování
Po připojení dat je vhodné zkontrolovat, zda všechny prvky mají přiřazen záznam z párované tabulky. Důvodem může být chyba v datech anebo změna v metodice, která vede k změnám v kódech. Obě situace by se měli hlídat.
Pro jednoduché zobrazení skupin je možné využít nastavení symbologie. Ve se nastaví Kategorizovaný typ.
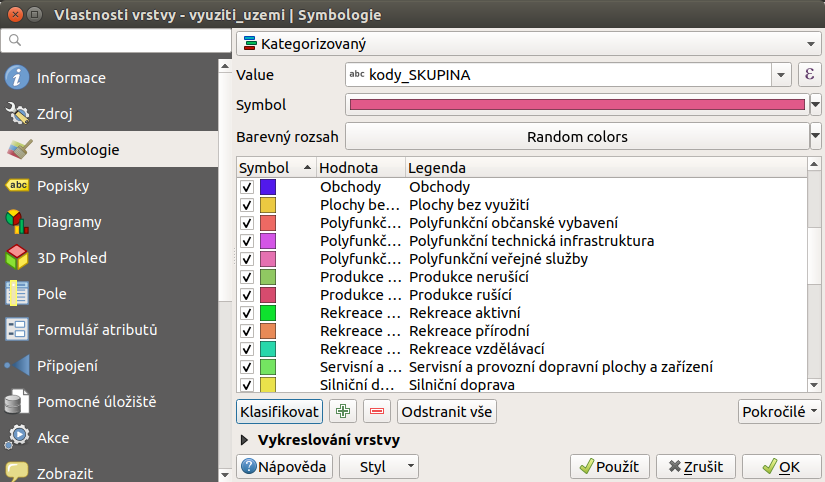
Obr. 203 Nastavení symbologie podle skupin kódů.¶
2. propojení dat využití území a členění¶
Druhým krokem je určit každé ploše příslušnou jednotku ZSJ pod kterou spadá. Pokud jedna plocha spadá do vícero území, tak toto musí být rozděleno hranicí a každá část bude mít správné uzemní přiřazení. Plochy, které leží mimo zájmové území se nebude používat - vypadnou. Tento požedavek splňuje operace Protnutí (intersection).
Vstupní vrstva je vyuziti_uzemi, překryvná je zsj. Výstup je v tomto případě uložen do GPKG.
Obr. 204 Nastavení nástroje protnutí.¶
Pro každou ZSJ je teď možné spočíst plochu ze všech dílčích plošek a nasčítat celkovou plochu pro všechny skupiny v ní zastoupené.
3. sumarizace podle skupin v ZSJ v procentech¶
Pomocí funkce Rozpustit (dissolve) je možné sloučit všechny plochy v rámci každé ZSJ spadající do stejné kategorie. Klíčové atributy jsou v tomto případě dva - identifikace ZSJ a identifikace skupiny - kod_zsj,`kody_skupina`.
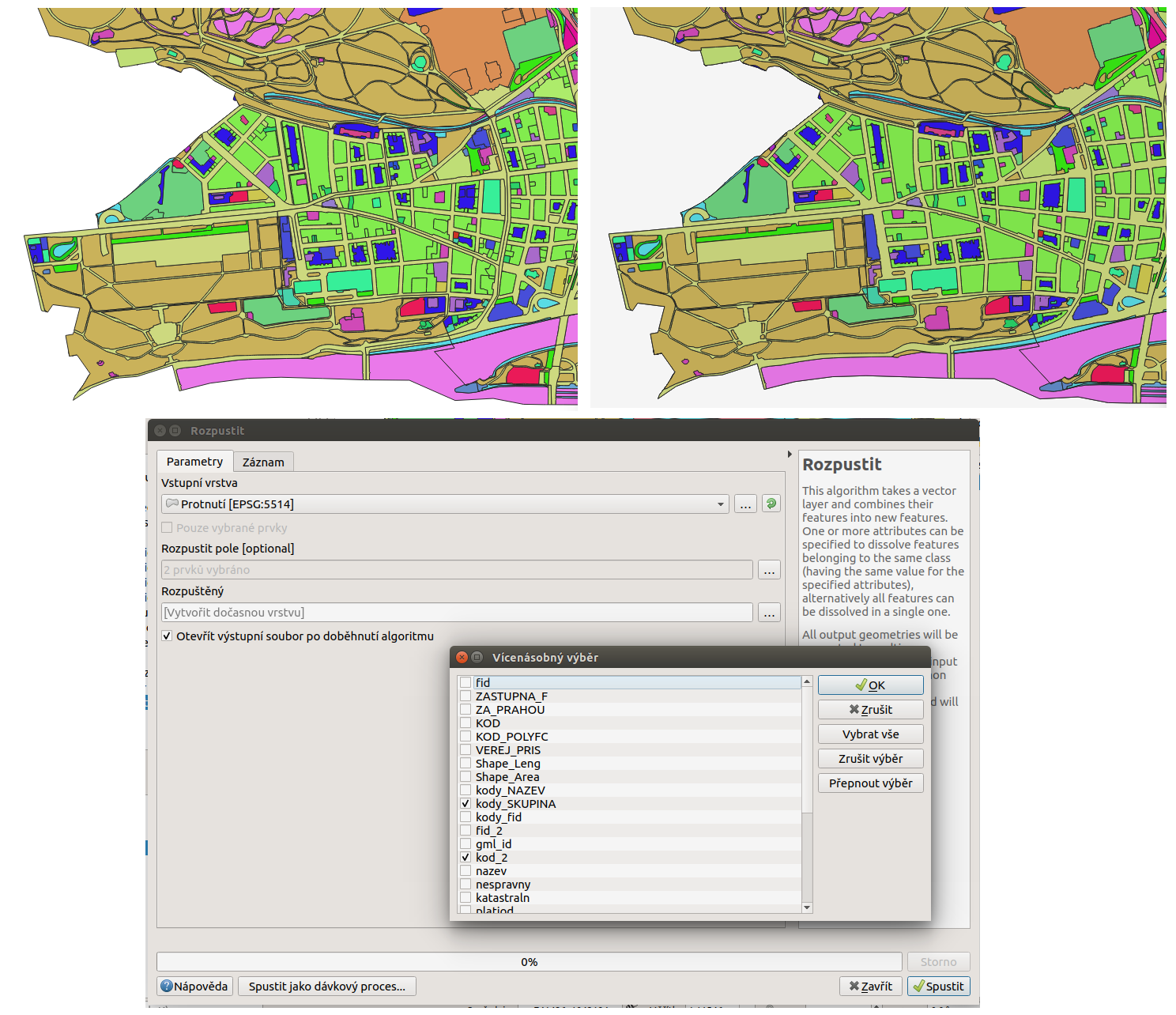
Obr. 205 Plochy v zájmovém území před a po sloučení, výběr atributů při použití nástroje.¶
Dalším krokem je výpočet procentuálního zastoupení dané skupiny. Přidá se nový atribut podil, který má datový typ desetinné číslo a požadovaný počet desetinných míst. Pomocí výrazu $area/“vymera_vypocet“*100 je možné spočítat procentuální podíl dané skupiny ploch na ploše ZSJ.
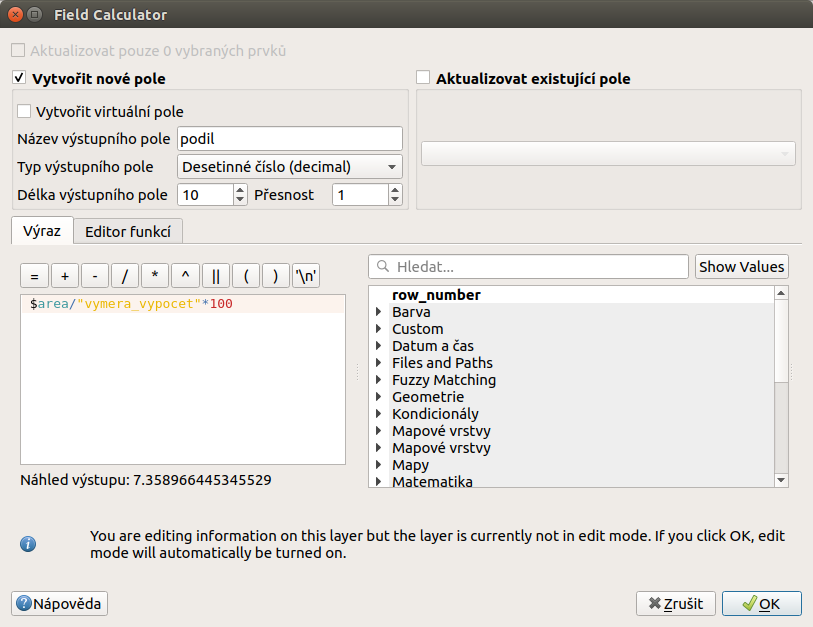
Obr. 206 Výpočet nového atributu s podílem dané skupiny v procentech.¶
4. přehledné zobrazení výsledků¶
Pro pěhledné zobrazení statistiky za každou ZSJ je vhodné tabulku upravit. Jedná se o tzv. pivotování. Kdy se vytvoří slopce pro hodnoty z vybraných sloupců. Na tento úkol se použije zásuvný modul Group Stats, který se přidá standardním způsobem. Plugin rovnou spustíme.
Jako první je nutné vybrat vrstvu, se kterou chceme pracovat. V tomto případě se jedné o výsledek z minulého kroku - výsledek po rozpůštění s nově přidaným sloupcem. Celý proces nastavení záleží na požadavcích a je možné použít i jiný postup.
Postupně je nutné zadat sloupce, které se zachovají - sekce Rows. Zde vybereme základní sloupce pro identifikaci ZSJ (nazev, kod_2, vymera).
Druhý požadavkem je zadání sloupců, ze kterých hodnot se vygenerují nové samostatné sloupce. V tomto případě chceme sloupce za každou skupinu. Do sekce Columns proto vybereme kody_SKUPINA.
Předpis pro výpočet se zadává do sekce Value. Pro tento příklad chceme, zby se spočetl podíl za každou skupinu. Vložíme tedy hodnoty podil a sum. V tomto případě je podil atribut spočtený v předchozím korku a sum je řídící funkce použitá pro přepočet - jednotlivé položky se budou sčítat.
Po zadání všech potřebných parametrů se aktivuje tlačítko Calculate, které pro zadané parametry spočítá požadovaný výsledek.
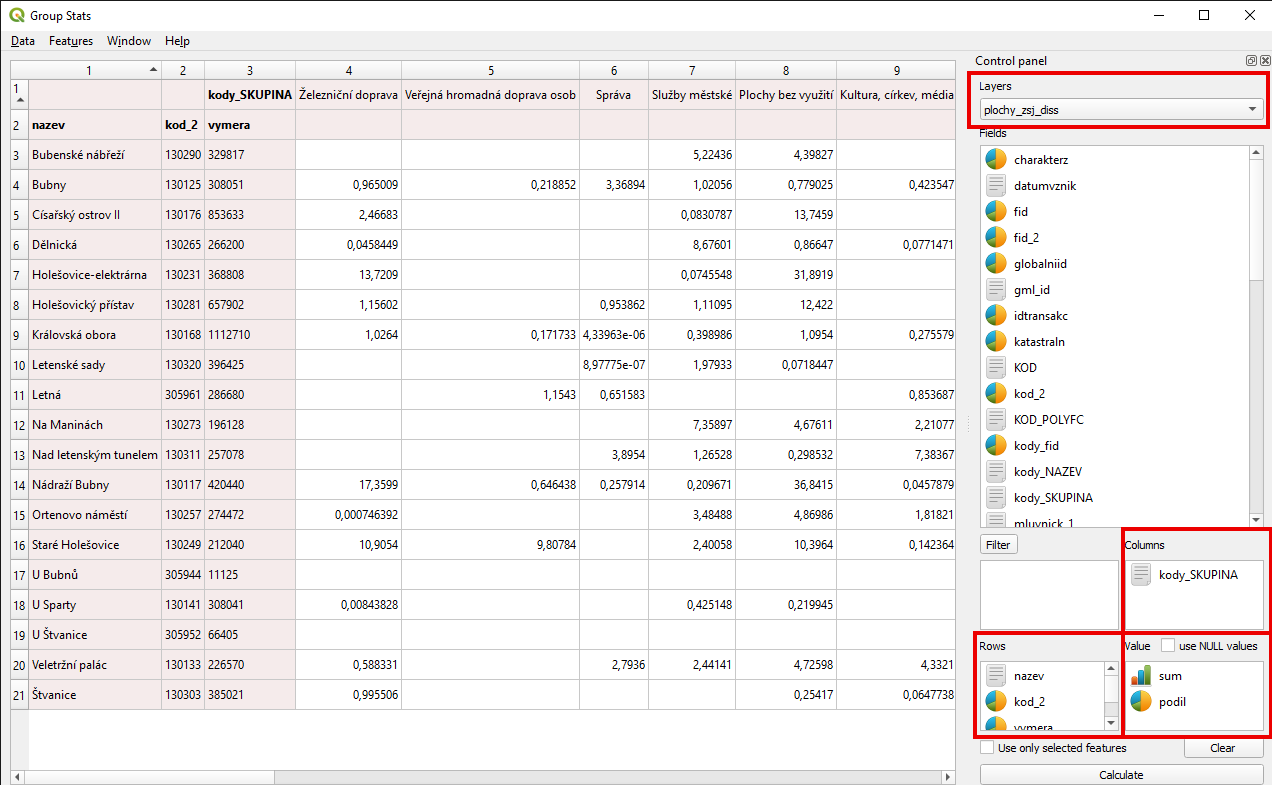
Obr. 207 Pivotování tabulky pomocí nástroje Group Stats.¶
V náhledu je vidět zachované sloupce, ty nově vytvořené z hodnot v sloupci kody_SKUPINA a dopočtené hodnoty.
Data zle zkopírovat, nebo uložit jako CSV. V tabulkovém editoru je pak možné dále upravovat dle potřeby.
Tip
Pro přehledné zobrazení je možné tabulku zpátky navázat na ZSJ a například pomocí kartodiagramu symbolizovat jednotlivé poměry zastoupení.