Metoda SCS CN¶
Teoretický základ¶
Jde o výpočet přímého odtoku z povodí, který je tvořen tzv. povrchovým odtokem a hypodermeckým (podpovrchovým) odtokem. Metoda byla vypracovaná službou na ochranu půd Soil Conservation Service (SCS CN) v USA. Objem srážek je na objem odtoku převedený na základě hodnot odtokových křivek CN, které jsou tabelizovány na základě hydrologických vlastností půd. Metoda zohledňuje závislost retence (zadržování vody) hydrologických vlastností půd, počáteční nasycení a způsob využívaní půdy. Hodnota CN křivek reprezentuje vlastnost povodí a platí, že čím je hodnota CN vyšší, tím je vyšší pravděpodobnost, že při srážkové události dojde k přímému odtoku.
Hodnota CN závisí na kombinaci hydrologické skupiny půd a způsobu využití území v daném místě. Kód hydrologické skupiny půd je získaný z dat hlavních půdních jednotek (přesnější způsob) anebo dat komplexního průzkumu půd (tam, kde informace o hlavních půdních jednotkách nejsou k dispozici).
Základní symboly¶
\(CN\) - hodnota odtokové křivky
\(A\) - maximalní potenciální ztráta z povodí, výška vody zadržané v povodí; ostatní je odtok (\(mm\))
\(I_a\) - počítaná ztráta z povodí, když ještě nedochází k odtoku (\(mm\))
\(H_s\) - návrhová výška srážky, zátěžový stav (\(mm\))
\(H_o\) - výška přímého odtoku (\(mm\))
\(O_p\) - objem přímého odtoku (\(m^3\))
Platí, že poměr mezi skutečnou a maximální ztrátou z povodí je stejný jako poměr odtoku a srážky, která je redukovaná o počáteční ztraty.
Vstupní data¶
hpj.shp - vektorová vrstva hlavních půdních jednotek z kodů BPEJ, Obr. 18 vlevo
kpp.shp - vektorová vrstva komplexního průzkumu půd, Obr. 18 vpravo
landuse.shp - vektorová vrstva využití území, Obr. 19 vlevo
povodi.shp - vektorová vrstva povodí IV. řádu s návrhovými srážkami \(H_s\) (doba opakovaní 2, 5, 10, 20, 50 a 100 rokov), Obr. 19 vpravo
hpj_hydrsk - číselník s hydrologickými skupinami půd pro hlavní půdní jednotky, Obr. 20 vlevo
kpp_hydrsk - číselník s hydrologickými skupinami půd pro vrstvu komplexního průzkumu půd, Obr. 20 uprostřed
lu_hydrsk_cn - číselník s hodnotami CN pro kombinaci využití území a hydrologické skupiny, Obr. 20 vpravo
Poznámka
Vrstvu povodí je možno získat z volně dostupné databáze DIBAVOD. Bonitované půdní ekologické jednotky - dvě číslice pětimístného kódu udávající hlavní půdní jednotku, informace o využití území Land Parcel Identification System a data komplexního průzkumu půd poskytuje většinou krajský úřad příslušného území. Návrhové srážky je možno získat z hydrometeorologického ústavu.
Navrhovaný postup¶
1. sjednocení hlavních půdních jednotek a komplexního průzkumu půd
2. připojení informací o hydrologické skupině
3. průnik vrstvy hydrologických skupin s vrstvou využití území
4. připojení hodnot odtokové křivky \(CN\)
5. sjednocení průniku vrstvy hydrologických skupinami a využití území s vrstvou povodí
6. výpočet výměry elementárních ploch, parametru \(A\) a parametru \(I_a\)
7. výpočet parametru \(H_o\) a parametru \(O_p\) pre každou elementární plochu
8. vytvoření rastrových vrstev výšky a objemu přímého odtoku
9. výpočet průměrných hodnot výšky a objemu přímého odtoku pro povodí
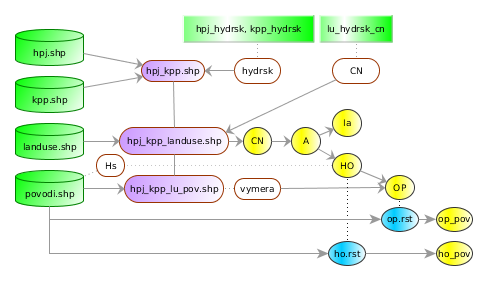
Obr. 17 Grafické schéma postupu.¶
Znázornění vstupních dat spolu s atributovými tabulkami je uvedeno na Obr. 18 a Obr. 19. Tabulky s informacemi o hydrologické skupině půdy a o hodnotách CN pro kombinaci využití území a hydrologické skupiny, resp. číselníky jsou na Obr. 20.
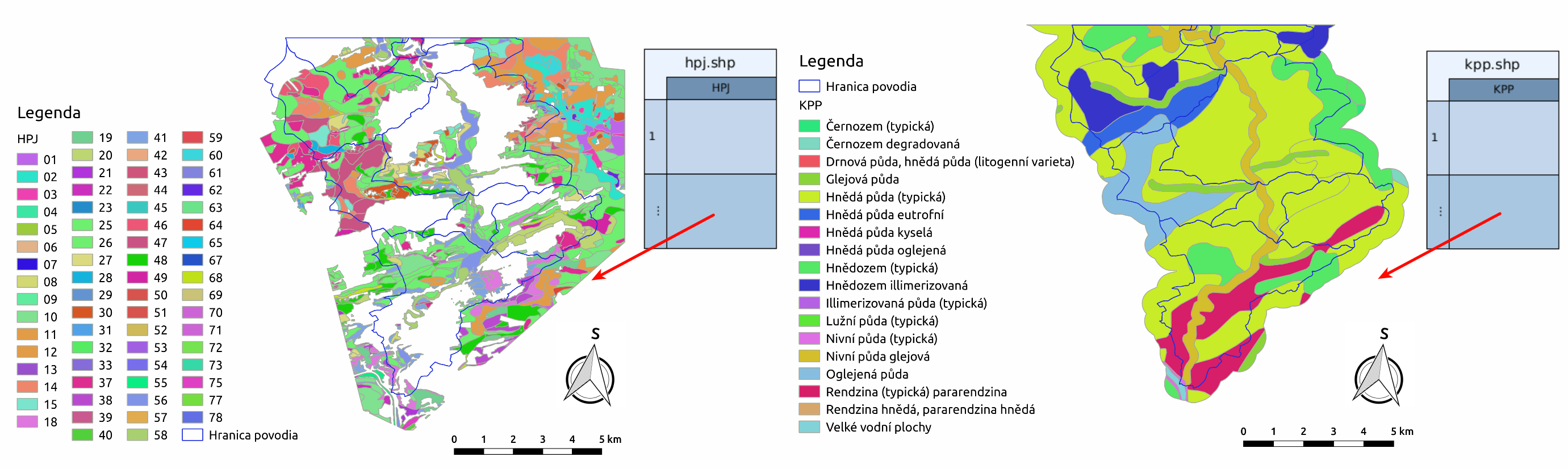
Obr. 18 Hlavní půdní jednotky a podrobný průzkum půd spolu s jejich atributovými tabulkami.¶
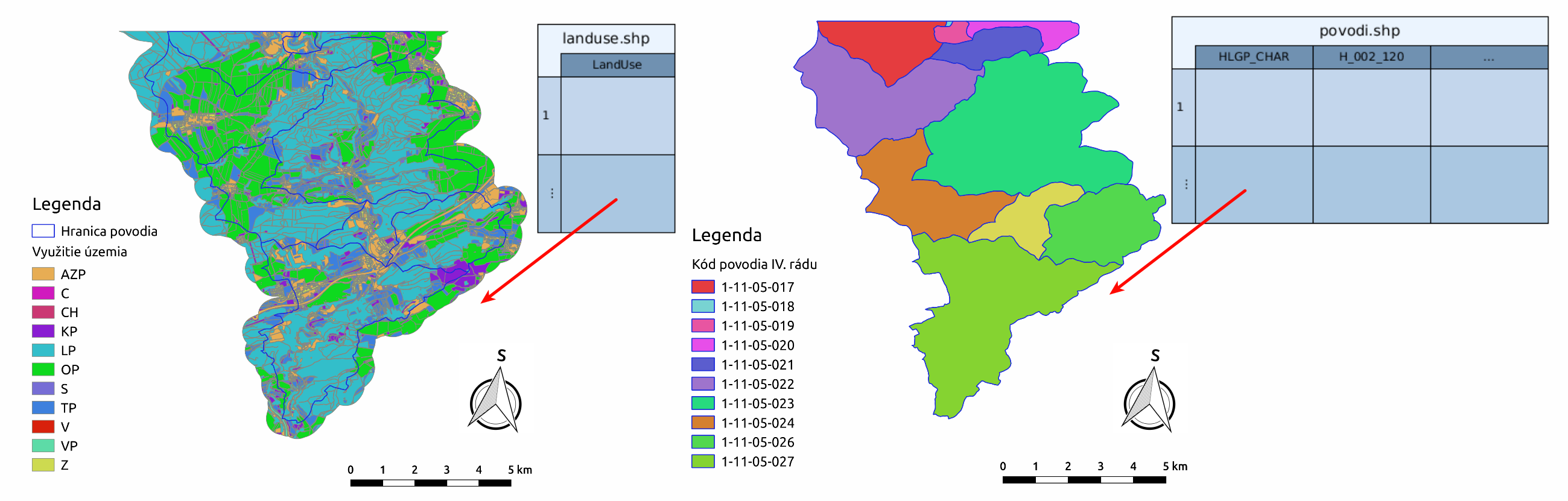
Obr. 19 Využití území a vrstva povodí IV. řádu spolu s jejich atributovými tabulkami.¶
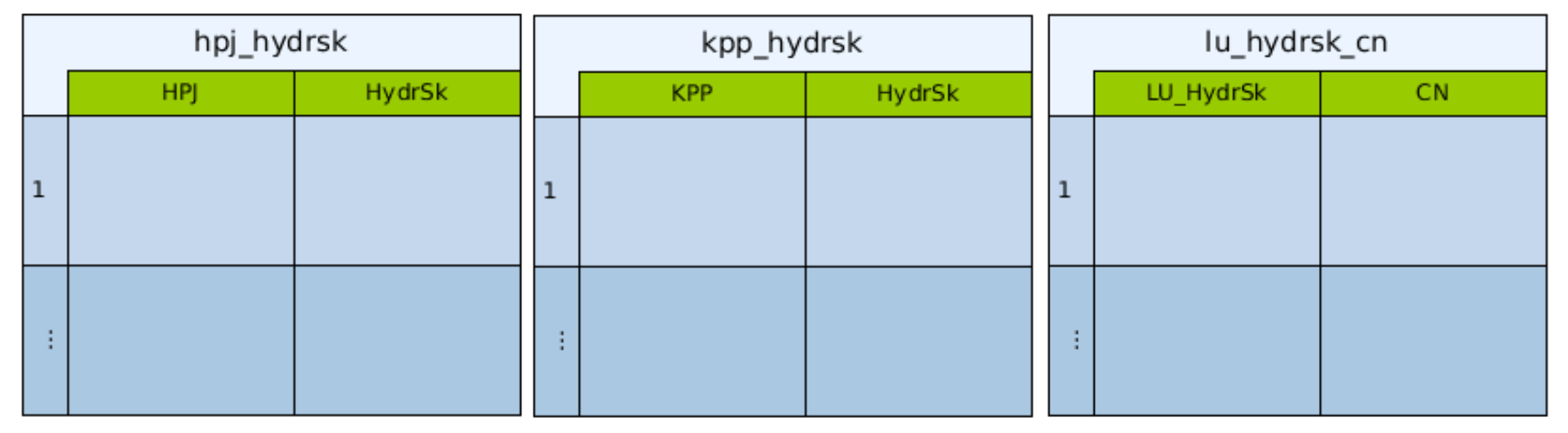
Obr. 20 Číselníky s informacemi o hydrologické skupině a hodnotami CN.¶
Postup zpracování v GRASS GIS¶
Krok 1¶
V prvním kroku sjednotíme vrstvu hlavních půdních jednotek a komplexního průzkumu půd. Použijeme modul v.overlay a operaci překrytí union.
v.overlay ainput=hpj binput=kpp operator=or output=hpj_kpp
Dále importujeme číselníky (db.in.ogr):
db.in.ogr input=hpj_hydrsk.csv output=hpj_hydrsk
db.in.ogr input=kpp_hydrsk.csv output=kpp_hydrsk
Zkontrolujeme obsah importovaných číselníků (tabulek) v prostředí GRASS GIS, případně aspoň jejich sloupů. Použijeme moduly db.select a db.columns.
db.select table=hpj_hydrsk
db.select table=kpp_hydrsk
db.columns table=hpj_hydrsk
db.columns table=kpp_hydrsk
Poznámka
V atributové tabulce hlavních půdních jednotek hpj_hydrsk je
po importu datový typ atributu HPJ jako typ DOUBLE
PRECISION (příkaz db.describe table=hpj_hydrsk); je
potřebné jej překonvertovat na celočíselný typ, t.j. INTEGER
(kvůli spojení tabulek a číselníků pomocí
v.db.join). Použijeme ALTER pro vytvorení
atributu HPJ_key a UPDATE pro naplnění hodnot
atributu.
db.execute sql="alter table hpj_hydrsk add column HPJ_key int"
db.execute sql="update hpj_hydrsk set HPJ_key = cast(HPJ as int)"
Po úpravě tabulky hpj_hydrsk můžeme tuto tabulku připojit k atributům vektorové mapy hpj_kpp pomocí klíče, konkrétně atributu HPJ_key.
v.db.join map=hpj_kpp column=a_HPJ other_table=hpj_hydrsk other_column=HPJ
Atributy v tabulce hpj_kpp po spojení zkontrolujeme či obsahují sloupce z číselníku a následně doplníme chybějící informace o hydrologické skupině HydrSk pomocí kpp_hydrsk. Doplníme je ze sloupce First_Hydr vrstvy komplexního průzkumu půd. Využijeme modul db.execute a SQL příkaz JOIN.
db.execute sql="UPDATE hpj_kpp SET HydrSk = (SELECT b.HydrSk FROM hpj_kpp AS a JOIN kpp_hydrsk as b ON a.b_KPP = b.KPP) WHERE HydrSk IS NULL"
Obsah atributové tabulky hpj_kpp zkontrolujeme pomocí SQL Query Builder a ověříme, zda všechny hodnoty hydrologické skupiny jsou vyplněné.
SELECT cat,HydrSk FROM hpj_kpp WHERE HydrSk is NULL
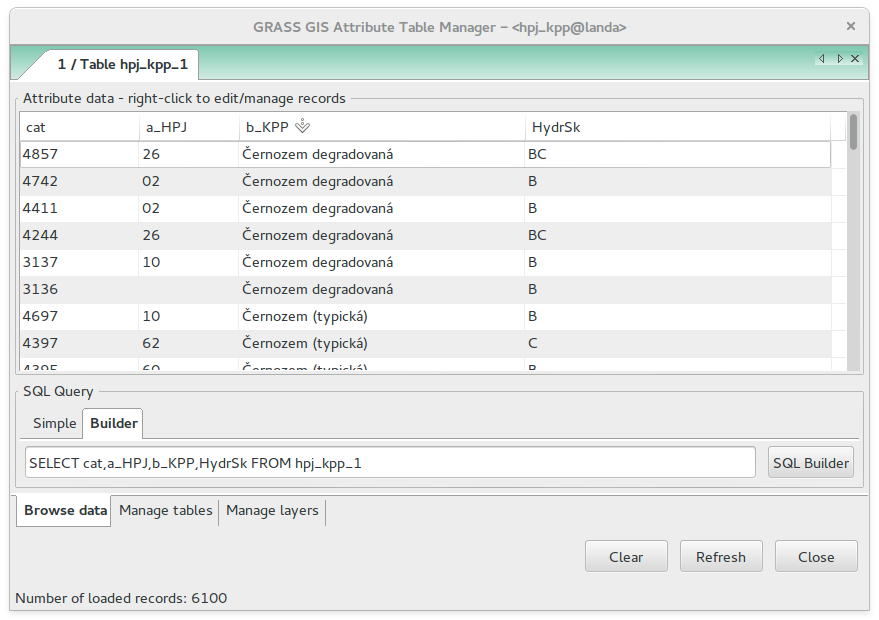
Obr. 21 Atributový dotaz s výsledkem hydrologické skupiny půd.¶
Nastavíme tabulku barev pro jednotlivé skupiny pomocí modulu v.colors. Kódy nelze použít, neboť tento modul podporuje pouze celočíselné hodnoty, proto je potřebné vytvořit nový atribut s jedinečnými hodnotami pro kódy. Nazveme ho HydrSk_key a bude obsahovat čísla 1 až 7 odpovídající kódům A až D. Použijeme moduly v.db.addcolumn a db.execute a příkaz UPDATE jazyka SQL.
v.db.addcolumn map=hpj_kpp columns="HydrSk_key int"
db.execute sql="update hpj_kpp set HydrSk_key = 1 where HydrSk = 'A';
update hpj_kpp set HydrSk_key = 2 where HydrSk = 'AB';
update hpj_kpp set HydrSk_key = 3 where HydrSk = 'B';
update hpj_kpp set HydrSk_key = 4 where HydrSk = 'BC';
update hpj_kpp set HydrSk_key = 5 where HydrSk = 'C';
update hpj_kpp set HydrSk_key = 6 where HydrSk = 'CD';
update hpj_kpp set HydrSk_key = 7 where HydrSk = 'D'"
Poznámka
Nový sloupec je možné přidat i pomocí správce atributových dat.
Do textového souboru colors.txt vložíme pravidla vlastní
barevné stupnice pro jednotlivé kategorie.
1 red
2 green
3 yellow
4 blue
5 brown
6 orange
7 purple
Modulem g.region nastavíme výpočetní region na vektorovou mapu hpj_kpp a konvertujeme vektorovou vrstvu na rastrovou, přiřadíme barevnou škálu a doplníme mimorámové údaje jako legendu a měřítko. Pro rasterizaci použijeme vhodné prostorové rozlišení, v našem případě 10m.
Poznámka
Vektorovou vrstvu konvertujeme kvůli tomu, neboť zobrazit legendu je možné pouze pro rastrové data.
g.region vector=hpj_kpp res=10
v.to.rast input=hpj_kpp output=hpj_kpp_rst use=attr attribute_column=HydrSk_key
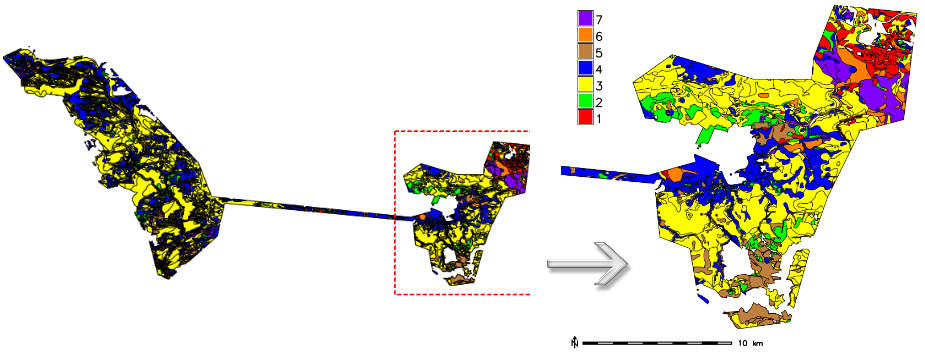
Obr. 22 Výsledná vizualizace hydrologických skupin půd (1: A, 2: AB, 3: B, 4: BC, 5: C, 6: CD a 7: D).¶
Přidáme informace o využití území pro každou plochu pomocí operace průniku intersection s datovou vrstvou využití území landuse.
v.overlay ainput=hpj_kpp binput=landuse operator=and output=hpj_kpp_land
Přidáme sloupec LU_HydrSk s informacemi o využití území a hydrologické skupině pro každou elementární plochu. Hodnoty budou ve tvaru VyužitíÚzemí_KodHydrologickéSkupiny, t.j. LU_HydrSk.
v.db.addcolumn map=hpj_kpp_land columns="LU_HydrSk text"
db.execute sql="update hpj_kpp_land set LU_HydrSk = b_LandUse || '_' || a_HydrSk"
Poznámka
Tuto operaci je možné provést i pomocí správce atributových dat (Field Calculator)
Pomocí modulu db.select anebo pomocí správce atributových dat vypíšeme počet všech kombinácí v sloupci LU_HydrSk.
db.select sql="select count(*) as comb_count from (select LU_HydrSk from hpj_kpp_land_1 group by LU_HydrSk)"`
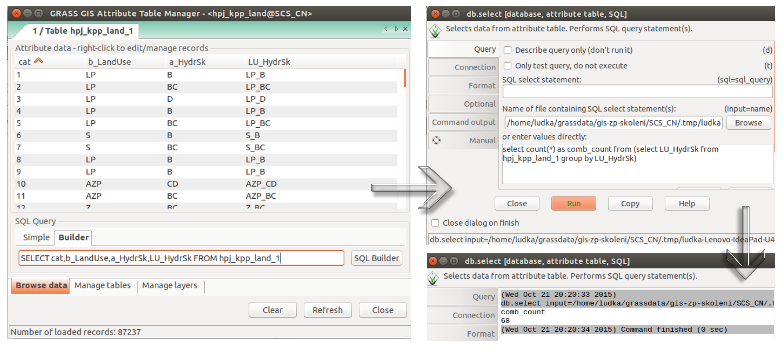
Obr. 23 Zobrazení části atributové tabulky a výpis počtu kombinací využití území a hydrologické skupiny.¶
Určíme odpovídající hodnoty \(CN\). Importujeme je do souboru LU_CN.xls a následně připojíme pomocí v.db.join.
db.in.ogr input=lu_hydrsk_cn.csv output=lu_hydrsk_cn
v.db.join map=hpj_kpp_land column=LU_HydrSk other_table=lu_hydrsk_cn other_column=LU_HydrSk subset_columns=CN
Výsledné informace jako kód hydrologické skupiny, kód využití území
a kód \(CN\) zobrazíme v atributové tabulce SQL dotazem
SELECT cat,a_HydrSk,b_LandUse,CN FROM hpj_kpp_land_1.
Následně vytvoříme rastrovou vrstvu s hodnotami \(CN\).
g.region vector=hpj_kpp_land res=10
v.to.rast input=hpj_kpp_land output=hpj_kpp_land_rst use=attr attribute_column=CN
r.colors -e map=hpj_kpp_land_rst color=aspectcolr
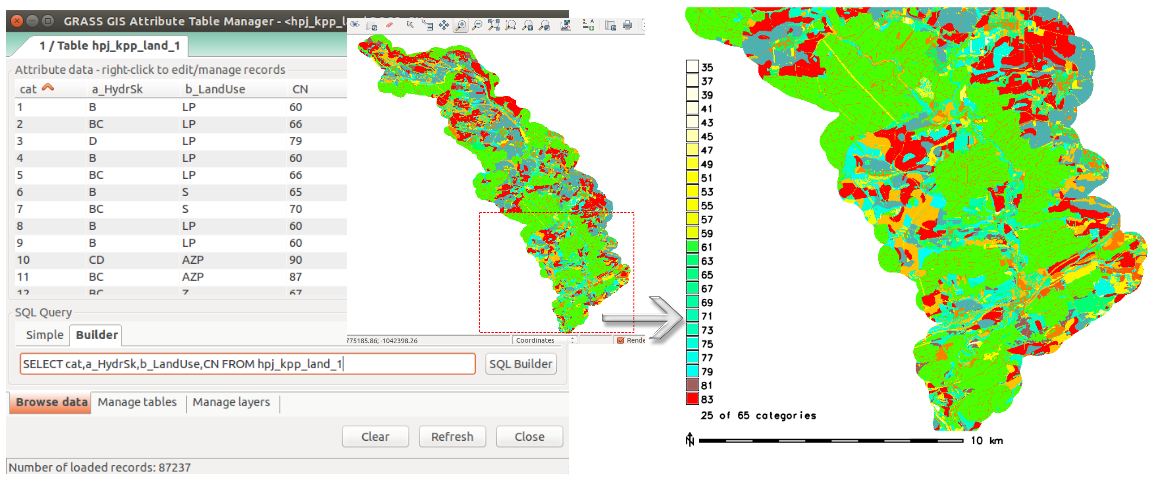
Obr. 24 Kódy \(CN\) pro každou elementární plochu využití půdy v zájmovém území.¶
Atributová tabulka vrstvy povodi obsahuje údaje o návrhových srážkách s dobou opakovaní 5, 10, 20, 50 a 100 let. Je potřebné přidat tuto informaci ke každé elementární ploše.
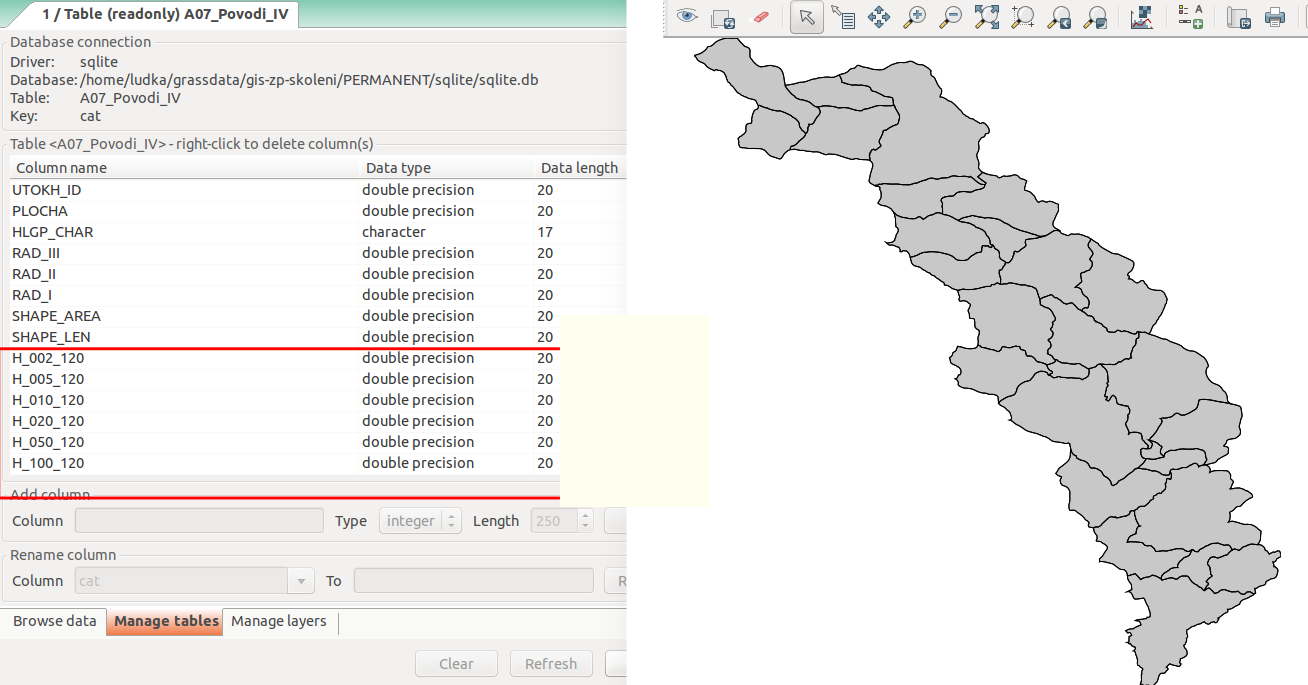
Obr. 25 Atributy související s návrhovými srážkami s různou dobou opakovaní.¶
Vrstvu hpj_kpp_land sjednotíme s vrstvou povodi, na což využijeme modul v.overlay.
v.overlay ainput=hpj_kpp_land binput=povodi operator=or output=hpj_kpp_land_pov
Po sjednotení vidíme, že došlo k rozdělení území na menší plochy. Přesný počet je možné zjistit použitím db.select.
db.select sql="select count (*) as elem_pocet from hpj_kpp_land_1"
db.select sql="select count (*) as elem_pocet from hpj_kpp_land_pov_1"
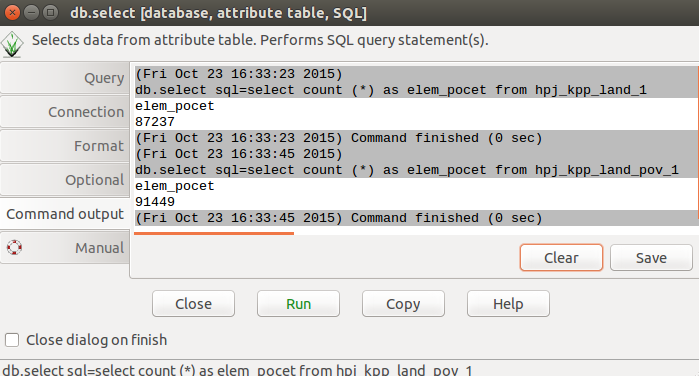
Obr. 26 Počet elementárních ploch před a po sjednocení s vrstvou povodí.¶
Kroky 2 a 3¶
Pro každou elementární plochu vypočítame její výměru, parametr \(A\) (maximální ztráta) a parametr \(I_{a}\) (počáteční ztráta, což je 5 % z \(A\))
Do atributové tabulky hpj_kpp_land_pov přidáme nové sloupce vymera, A, I_a vypočítame výměru, parametr \(A\) a parametr \(I_{a}\).
v.db.addcolumn map=hpj_kpp_land_pov columns="vymera double,A double,I_a double"
v.to.db map=hpj_kpp_land_pov option=area columns=vymera
v.db.update map=hpj_kpp_land_pov column=A value="24.5 * (1000 / a_CN - 10)"
v.db.update map=hpj_kpp_land_pov column=I_a value="0.2 * A"
Kroky 4 a 5¶
Přidáme další nové sloupce do atributové tabulky o parametry \(H_{o}\) a \(O_{p}\) a vypočítame jejich hodnoty pomocí v.db.update.
Poznámka
V dalších krocích budeme uvažovat průměrný úhrn návrhové srážky \(H_{s}\) = 32 mm. Při úhrnu s dobou opakovaní 2 roky (atribut H_002_120) či dobou 5, 10, 20, 50 anebo 100 let by byl postup obdobný.
Poznámka
Hodnota v čitateli musí být kladná, resp. nesmíme umocňovat záporné číslo. V připadě, že čitatel je záporný, výška přímého odtoku je rovná nule. Pro vyřešení této situace si pomůžeme novým sloupcem v atributové tabulce, který nazveme HOklad.
v.db.addcolumn map=hpj_kpp_land_pov columns="HOklad double, HO double, OP double"
v.db.update map=hpj_kpp_land_pov column=HOklad value="(32 - 0.2 * A)"
db.execute sql="update hpj_kpp_land_pov_1 set HOklad = 0 where HOklad < 0"
v.db.update map=hpj_kpp_land_pov column=HO value="(HOklad * HOklad) / (32 + 0.8 * A)"
Nakonec vypočítáme objem \(O_{p}\) a výsledky zobrazíme v rastrové podobě.
v.db.update map=hpj_kpp_land_pov column=OP value="vymera * (HO / 1000)"
v.to.rast input=hpj_kpp_land_pov output=HO use=attr attribute_column=HO
v.to.rast input=hpj_kpp_land_pov output=OP use=attr attribute_column=OP
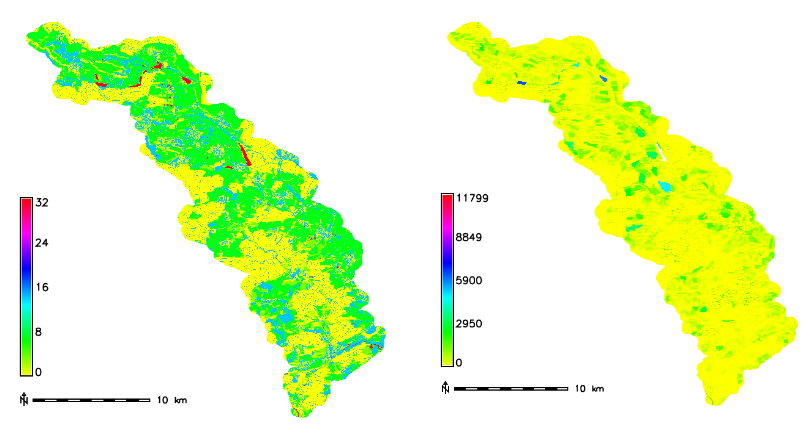
Obr. 27 Výška v mm vlevo a objem v \(m^{3}\) vpravo přímého odtoku pro elementární plochy.¶
Vypočítame a zobrazíme průměrné hodnoty přímého odtoku pro jednotlivé povodí. Přitom je potrebné nastavit rozlišení výpočetního regionu, překopírovat mapu povodí do aktuálneho mapsetu a nastaviť vhodnou barevnost výsledku.
g.region vector=kpp res=10
v.rast.stats map=povodi raster=HO column_prefix=ho
v.to.rast input=povodi output=HO_pov use=attr attribute_column=ho_average
r.colors map=HO_pov color=bcyr
v.rast.stats map=povodi raster=OP column_prefix=op
v.to.rast input=povodi output=OP_pov use=attr attribute_column=op_average
r.colors map=OP_pov color=bcyr
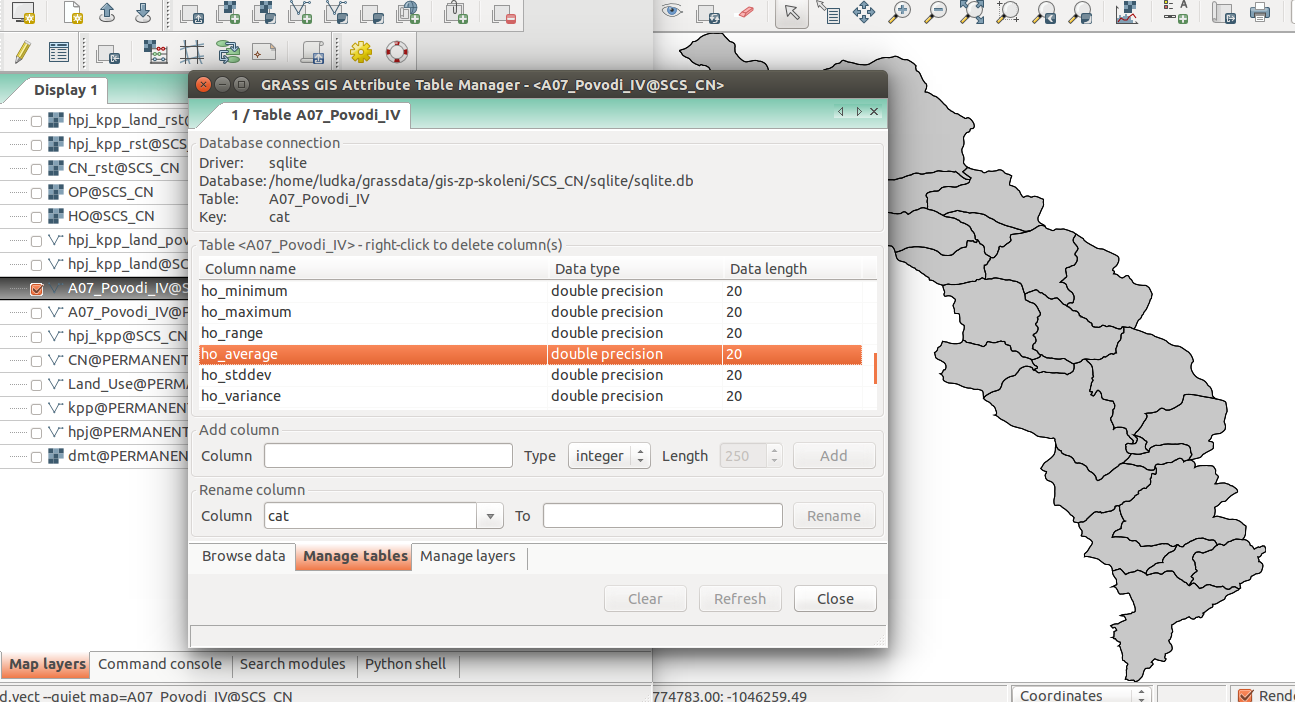
Obr. 28 Výpočet statistických údajů pro každé povodí.¶
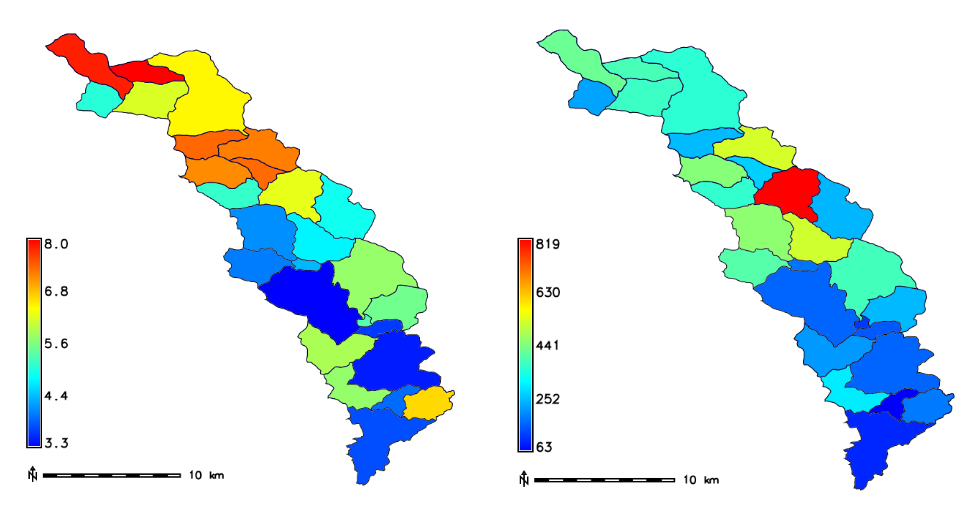
Obr. 29 Průměrná výška odtoku v \(mm\) a průměrný objem odtoku v \(m^{3}\) povodí v zájmovém území.¶
Výstupní data¶
hpj_kpp - sjednocení hpj a kpp (atributy aj z číselníku hpj),
hpj_kpp_land - průnik hpj_kpp a landuse,
hpj_kpp_land_pov - průnik hpj_kpp_land a povodi,
hpj_kpp_rst - rastr s hodnotami HydrSk,
hpj_kpp_land_rst - rastr s hodnotami CN,
HO, resp. HO_pov - rastr s výškou odtoku \(mm\) pro elementární plochy, resp. pre povodí,
OP, resp. OP_pov - rastr s hodnotami objemu odtoku v \(m^{3}\) pro elementární plochy, resp. povodí.
Použité zdroje¶
[1] HYDRO.upol.cz